之前我們分析了銀行等金融機構的運維組織架構現狀,討論運維組織敏捷化轉型的背景,最后解釋了什么是敏捷型的運維組織以及如何打造敏捷型的運維組織,本文我們重點來關注架構實施層面:金融業分布式系統運維實踐。
分布式系統,無論在互聯網行業亦或是傳統行業,都不再是新興事物,互聯網公司推行較早,傳統行業近幾年也開始發力建設。對于運維人來說,分布式系統的運維與傳統集群式系統的運維大相徑庭,我們今天就來探討一下分布式運維的建設。
01. 分布式運維的挑戰
1)分布式系統的定義
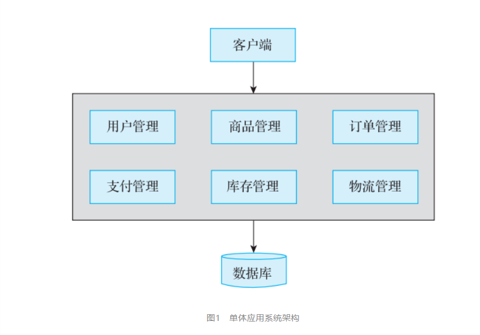
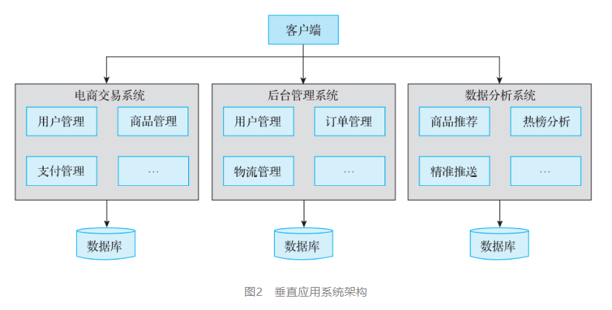
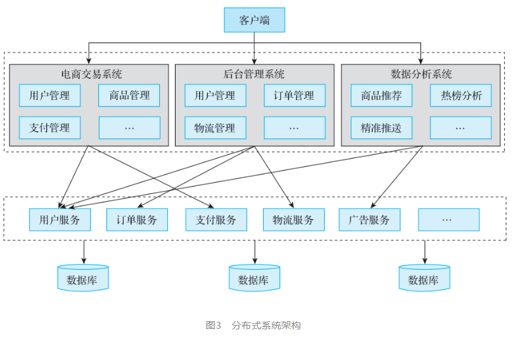
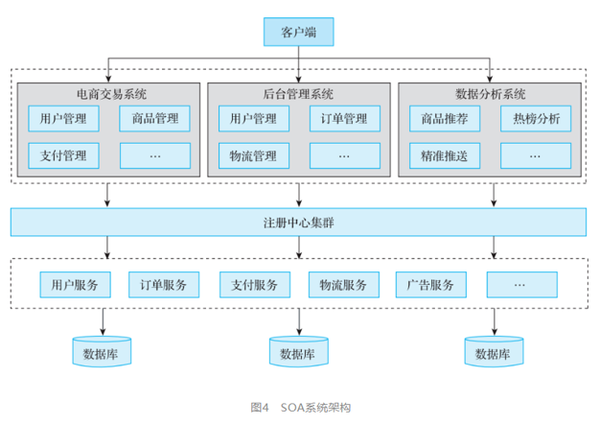
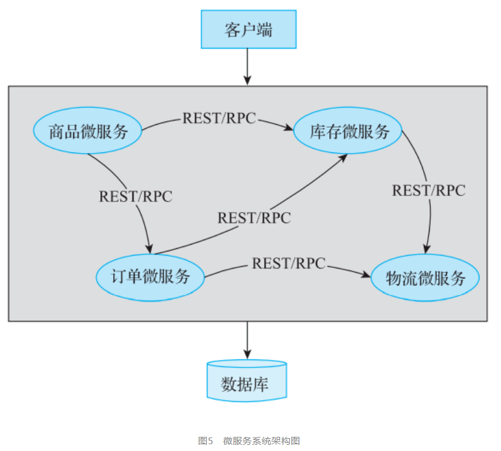
分布性:由多臺計算機組成,在地域上是分散的;系統功能分布在各個節點上,具有數據處理的分布性;
自治性:各個節點都包含自己的處理機和內存,具備獨立處理數據的功能,通常彼此地位平等,無主次之分;
并行性:一個大的任務可以劃分為若干個子任務,分別在不同的主機上執行;
全局性:存在單一的、全局的進程通信機制,使得任何一個進程都能與其他進程通信,并且不區分本地通信與遠程通信,同時還有全局的保護機制。
① 運維不確定性顯著增加:
系統中有大量的服務器及設備,各模塊之間存在錯綜復雜的依賴關系,存在更多的不確定性。
② 故障率指數級增加:
整個系統的故障率會隨設備的增加而呈指數級增加,單一節點問題可能會被無限放大,日常運行過程中一定會伴隨“異常”發生。
③ 運維日常復雜性大增:
分布式系統節點分布范圍更加廣,節點數量更多,物理位置不統一,非常依賴于網絡,這對日常運維過程中的日志采集、變更升級等都帶來了新的挑戰。
④ 運維架構復雜度:
隨著技術角色分工越來越細,技術專業化程度越來越深,分布式系統穩定性落地因其架構特性,對架構設計思路、組織設計等帶來了新的挑戰。
⑤ 運維新模式:
要保障分布式架構下的系統穩定性,需要系統化地探討穩定性建設新模式。
分布式系統建設追求穩定性,分兩個目標、四大模式、四項路徑。
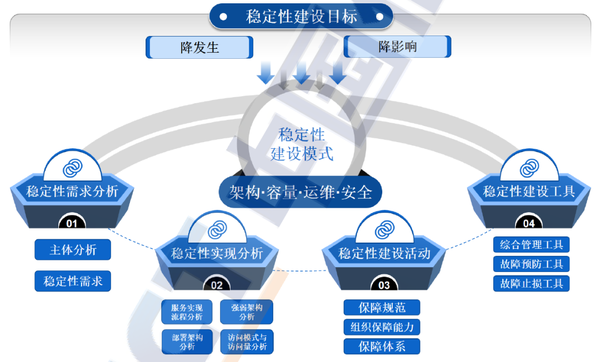
02. 穩定性建設目標
1)建設目標主要有兩個:
降發生:事前的管理,通過建設“高可用、高性能、高質量”的系統來降低故障發生的概率;
降影響:事后的管理,在故障發生后,“早感知、快定位、急止損、優改進”,降低影響范圍。
2)量化評價指標三個:
- 業務可用程度;
- 用戶影響程度;
- 資產損失程度。
03. 穩定性運維建設模式
分布式運維建設模式主要分為:架構設計、容量設計、運維設計、安全設計。我們主要看下和運維相關的要點。
1)架構設計
一般情況下,架構設計主要由研發部門主導,但是運維人員不能只是作為后端被動承接系統的運維,最好在架構設計階段就提出規范,滿足穩定性運維的要求:
① 去除單點

② 依賴設計
高等級服務不允許強依賴于低等級的服務或資源。

③ 數據保護
數據保護的主要目的是提升數據安全性,業界一般通過RPO(恢復點目標)與RTO (恢復時間目標)兩個指標進行度量,核心目標是盡可能縮短數據恢復時間(降低RTO),避免數據丟失(RPO接近于0)。
針對不同的業務系統、分布式系統里面不同的服務模塊,需要有對應級別的數據保護考量。
服務器單點保護:基于本地盤跨機房異步復制數據,但服務器出現不可恢復故障時將存在數據丟失
存儲單點保護:基于單存儲數據庫系統跨機房異步復制,但存儲出現不可恢復故障時將存在數據丟失
同機房內多點保護:基于同機房多點保護的數據庫系統,同機房多份redo及跨機房異步復制模式,但機房故障時存在數據丟失
同城異機房保護:基于同城異機房保護的數據庫系統,采取同城異機房內多份redo保護及跨機房DG,但城市出現災備時存在數據丟失
異地異機房保護:基于異地多點保護的數據庫系統,采取跨城跨機房數據保護,但出現人類災難時存在數據丟失
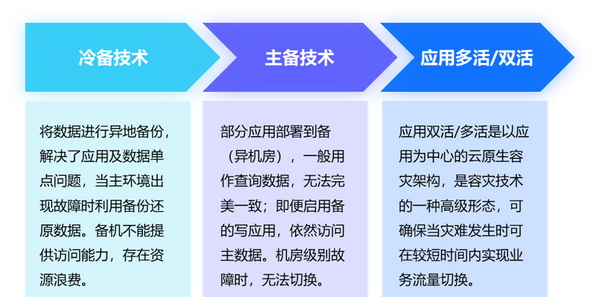
④ 災備設計
當故障或者災難發生時,可通過災備技術保證業務不中斷、數據不丟失。針對不同的業務場景,綜合成本與效果的考量,選擇相應的災備設計。
⑤ 彈性設計
- 故障隔離標準:防止故障傳播;
- 訪問量控制標準:對服務資源有效的SLA控制;
- 服務降級、限流與熔斷:保護系統影響進一步惡化;
- 容錯設計:本著不信任外部資源(外部服務、DB、網絡設備、存儲、消息等)100%可用的原則。
2)容量設計

系統上線之前,最好能有一個比較嚴謹的測試,比如全鏈路壓測,模擬用戶真實流量,對容量和性能等做測試。
3)運維方案設計
提前考慮系統上線后的運維訴求,做到變更可控、系統可觀、演練到位。
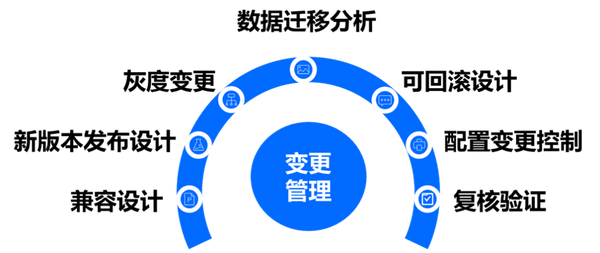
① 變更設計
分布式系統發布頻率較高、顆粒度較小、發布量較大,變更引起的系統問題一般占大部分比重,所以需要有一套嚴格的自動化發布機制。
② 可觀測設計
可觀測,以前叫監控告警,是分布式系統里面提出的一個新概念。應用系統觀測需要覆蓋的資源類型如下:

可觀測的核心主要是四個維度:拓撲、Metric指標、trcae鏈路、log日志。
橫向看,從業務訪問端到端的整個鏈路做數據的分析和展示,縱向看,把整個的資源、資源的指標和日志拉通;橫向是業務層次、縱向是技術層次,一橫一縱,就構成了可觀測。
③ 演練設計
相較傳統架構系統,分布式系統發生故障的概率較高,我們需要提前進行演練設計。

④ 安全設計
系統安全是系統穩定的基礎,主要有如下四個方面:
- A:系統設計安全
- B:部署和操作系統安全
- C:數據安全
- D:網絡安全
04. 分布式系統運維工具落地建設
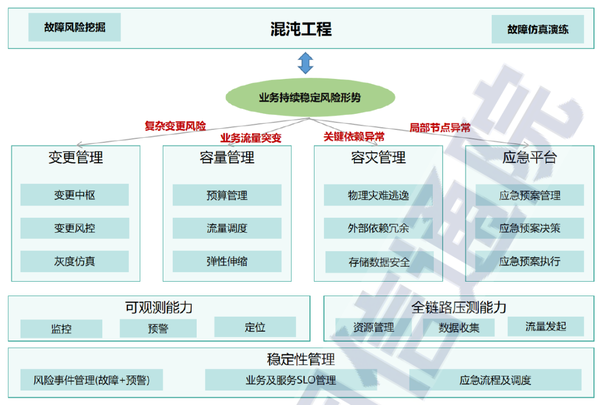
1)一體化綜合管理工具
微服務化日甚的當下,故障影響往往是復雜多樣的(單一節點故障可能導致全線業務出錯),往往需要多個技術團隊的協同保障系統穩定。需要統一的系統化穩定性管理能力作為“連接器”實現多團隊協同“透明化”作戰,并進一步通過故障應急過程及結果數據復盤,“數據化”風險趨勢以確定建設重點,“標準化”故障管理流程以提升故障管理效率,定義業務或服務的SLO ( Service Level Objective,服務等級目標)以“結構化”組織穩定性保障能力。

2)故障預防工具
① 可觀測能力
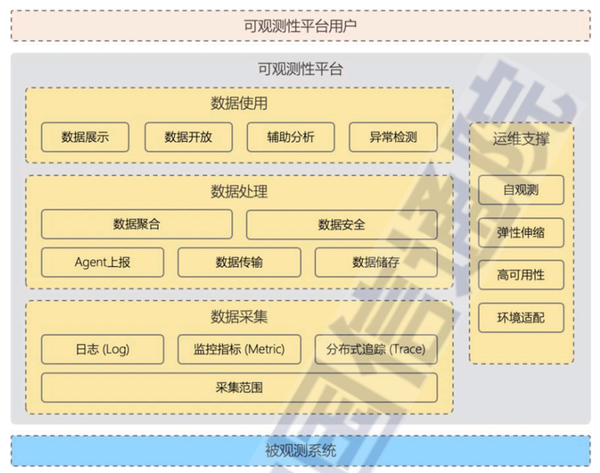
- 如果直接選用一套大數據平臺來進行全局可觀測能力的構建,幾乎是行不通的。主要原因在于:
- A:目前在銀行等企業里面,或多或少都已有Zabbix、APM等來自不同廠商的監控工具,數據格式等均不一樣,無法關聯
- B:市面上現有的大數據平臺,基本都是裸的或者比較笨重的大數據平臺,只對數據處理比較在行,但對不具備監控管理能力,如果啟用大數據平臺做監控數據的分析,需要先清理監控數據
- C:監控消費的場景是不斷增長的,后續的對接集成開發和維護成本非常高
那么比較好的建設模式甚至是最好的建設模式,是選一個具備大部分監控能力和數據處理的產品,同時兼容性較強,其他沒有的能力可以通過對接補足,這樣比較容易落地。
或者也可以選一個兼容性比較強的分析系統,本身能夠支持市面上常見的成熟產品,來做集中對接,這種方式也可行但相對難一點。
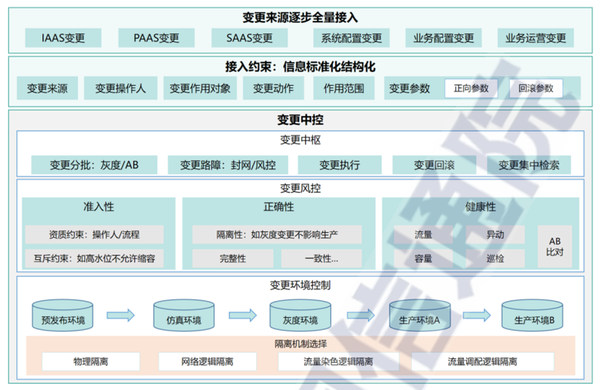
② 變更管理
變更管理能力建設中,信息標準化和變更風險控制屬于ITIL管理的范疇,全量接入、變更中控和變更環境控制屬于執行的范疇。
我們在實際落地的時候,屬于管理范疇的,建議在ITSM里面建設;屬于執行范疇的,在變更工具里面落地。
管理流程和管理工具,可以基于同一個運維管理平臺進行對接。
③ 容量管理
容量管理的核心有四個:
- A:容量需求;
- B:容量分析;
- C:容量調度;
- D:容量回收和清理。

④ 全鏈路壓測
通過全國各地CDN 節點模擬向生產系統施加壓力,模擬路演進行整體容量和穩定性驗證。全鏈路性能測試能力構建主要由以下幾部分構成:
- A:資源管理能力
- B:數據收集能力
- C:流量發起能力
- D:數據分析能力
- E:結果管理能力
- F:生產環境壓測改造

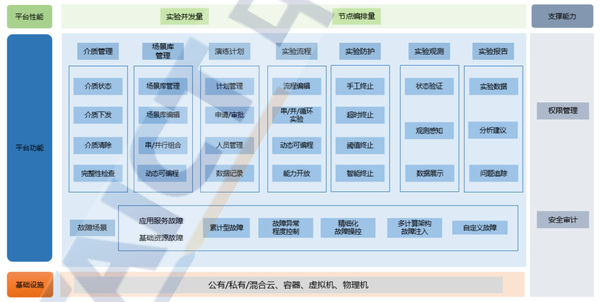
⑤ 混沌工程
如下圖所示混沌工程平臺能力,除此之外還需要在面向軟件完整生命周期、面向智能化、面向度量和運營能力體系建設三個方面進一步加強。
3)故障止損工具
① 應急平臺
應急平臺建設主要考慮以下方面:
- A:應用設計
- B:應急預案
- C:定期演練
- D:應急度量
- E:從手動應急到自動應急

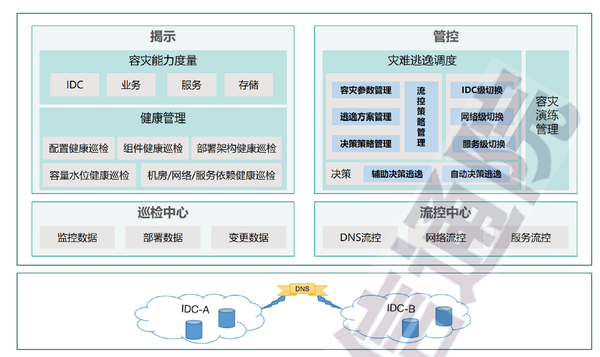
② 容災管理
容災管理主要分為容災揭示、容災管控兩部分,其中巡檢中心和流控中心作為容災揭示和容災管控的基礎工具依賴。
05. 總結
分布式系統運維與傳統運維的本質區別:
① 分布式系統運維:是面向應用可用性穩定性的,建設一體化能力。聚焦于穩定性,但建設圍繞點是從穩定性的背面“故障”出發。
② 傳統運維:主要面向基礎架構;建設cmdb\監控\自動化的豎井能力。
③ 本質上都還是監管控,但是需要有兩點:一是要融合并且面向應用;二是要升華,如APM、混沌工程、應用容量與成本等等。
④ 面向應用的混沌工程、應用容量、故障定位都需要監管控這些能力的融合。
⑤ 所有這些的實現都需要強有力的自動化運維平臺的支撐。











