近年來,可觀測性建設已經成為企業數字化轉型的高熱話題,但大多數企業在實踐落地過程中往往會發現,以往的建設模式并不能夠在企業中發揮良好的作用,單純的引入產品或工具已經沒有辦法達到建設需求。本期我們邀請到嘉為藍鯨運維產品負責人宋蘊真,從戰略管理,到組織度量,最后再到工具應用層面對可觀測落地實踐進行深度剖析,自上而下對可觀測落地建設進行梳理,帶您一步步深入探索可觀測性的落地實踐。
01. 戰略目標:服務于業務
數字化轉型是一個長期過程,早期企業IT運維主要還是面向物理設備,而隨著技術架構的不斷發展,運維對象逐漸向虛擬化、云化趨勢發展,軟件架構逐漸向SOA、云原生等架構轉變。業務的線上化趨勢下,傳統IT運維往往無法及時感知和處理問題,企業運維處于黑盒化狀態,在此背景下,運維管理體系需要向自動化、智能化轉型,以服務于快速發展的企業業務。
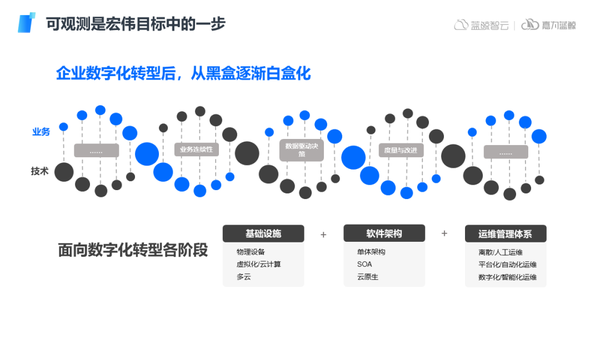
在數字化轉型過程中,運維的核心目標就是保障業務的連續性,IT運維整體的轉型戰略目標也需要始終服務于業務,在不同的建設階段通過不同方法和手段,快速的發現問題、解決問題可觀測是IT數字化轉型宏偉目標的其中一步,通過可觀測體系的建設,不斷提煉運維數據價值,幫助和驅動業務部門決策,并在這個過程中對IT組織進行持續的度量和改進,最終更好的推進企業數字化轉型宏偉目標的實現。
1)可觀測建設的核心目標與挑戰
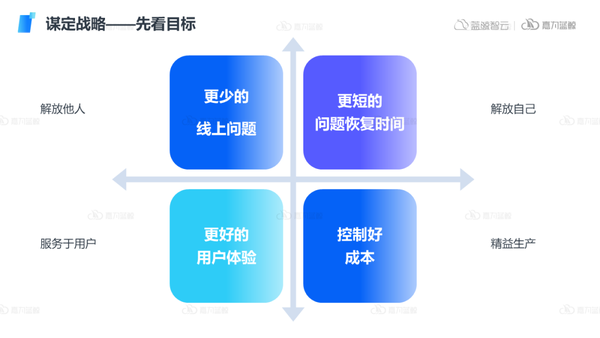
可觀測的建設是服務于業務的,首先需要細分并明確可觀測建設的核心目標。
- 更少的線上問題:當業務出現問題時,往往不是獨立存在的,可能會引起上下游的組織、業務、人員出現更多的問題,導致組織的效率低下或運維成本增加,而通過可觀測建設,減少問題的出現,能夠解放他人,讓更多的人員能夠投入到其他工作中,實現降本增效。
- 更短的問題恢復時間:IT業務幾乎無法避免問題的出現,SLO也不可能是100%,如何提早發現問題,更快的解決問題,或者采取自動化的方式處理重復工作,從而將運維人員自己解放出來,投入到更加價值的工作中,也是可觀測的核心目標之一。
- 更好的用戶體驗:業務最終是面向用戶的,通過可觀測的建設,提高系統穩定性和可用性,保障良好的用戶體驗,真正服務于用戶。
- 控制好成本:生產成本的控制往往也離不開可觀測,企業的降本增效需要IT能夠快速感知資源狀態,從而合理度量和分配IT資源,實現精益生產。
與此同時,云原生技術下的IT系統日益復雜,歷史系統、工具難以一時替換,而國產替代、自主可控又提出了新的要求,實現目標的挑戰也越來越大:
- 海量:面向大集群、多中心的集中觀測,技術挑戰、系統可用性挑戰高。
- 歷史包袱、煙囪林立:監控工具多,相互獨立,數據分散,管理復雜,煙囪林立。
- 工具聯動弱:運維工具難以互聯互通,監控處置慢,人員協同差,運維效率低,告警模式單一,無故障根源分析能力。
- 分布式系統日益復雜:運維對象日趨復雜,IT技術架構變化大,IT對象井噴式增長。
- 兼顧歷史與未來:既要能夠納管古老的IT對象,又要能夠納管先進的云原生、信創對象。
- 運維對業務的感知不足:運維側往往被動響應問題,需要從問題導向逐漸向主動地規劃導向演進。

02. 戰略拆分:問題處理的生命周期
確立總體服務與業務的戰略目標后,需要對目標進行一步步的拆分。通常情況下可觀測應用場景主要集中在處理IT運維問題上,而運維人員在工作中真正遇到故障時主要包括故障的發現、定位和恢復過程,但除了這些故障處理工作之外,故障提前預防以及故障事后復盤根治也是故障全生命周期中的重要環節。
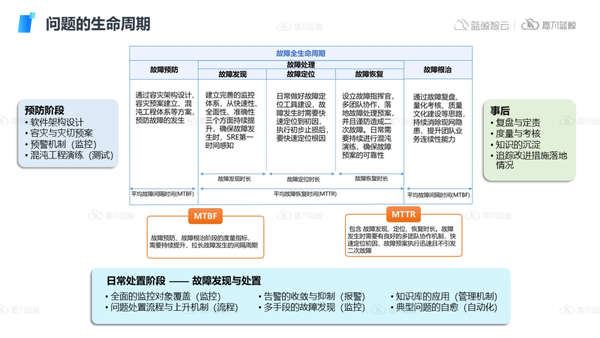
在不同的生命周期階段可觀測性也會有不同的關注點,我們需要把各個階段的目標進行細化,最終實現貫穿故障全生命周期的閉環處理,從而減少故障的發生頻率和故障恢復時間,提高運維整體效能。
1)預防階段
預防階段主要關注以下幾個方面,來降低故障發生的頻率,做好預防階段的規劃也是提高SLA的最根本的手段,通常這類規劃不會單獨由運維來執行,而是需要整體團隊協同配合,共同達成的目標。
2)軟件架構設計:
● 技術選型:選擇相對主流、穩定的基礎組件來構建生產系統。
● 易維護性:建立自身產品的可觀測,工具支持快速告警,支持干預,易恢復。
● 高可用設計:冗余設計與建立容災機制。
● 事務性:處理好分布式事務,保障數據一致性。
● 可擴展:對能力進行抽象與配置驅動,實現擴展性。
3)容災與災切:
● 容災:通過采取預防性措施,在系統發生故障時能夠順利恢復,從而避免系統癱瘓。常見的容災措施包括備份和恢復、冗余、負載平衡等
● 災切:在系統發生故障時,快速的切換到備用系統,避免業務中斷。通常需要在容災措施的基礎上進行,需要對備用系統進行定期測試和維護
4)預警機制:
● 定指標:利用觀測指標作為預警指標,可以是資源使用率或特定日志
● 設閾值:合理設置觸發閾值,考慮好檢測周期與指標周期的匹配
● 建流程:為不同級別的事件設計相應的處置流程,對于跨部門問題處理要建設問題支持工單流程。
5)混沌工程(測試):
● 目的:通過測試確保軟件質量,通過混沌工程提高軟件質量
● 方法:混沌工程通過模擬現實世界的混沌環境,來測試軟件的可靠性和可用性,而測試則是通過執行特定的測試用例,來檢驗軟件是否能夠滿足需求。
● 落地:大多數企業的業務規模下,我們需要做好測試工作,保障業務正常運轉。只有在一些互聯網企業,針對大型分布式系統時可能才會涉及到混沌工程的建設。

6)問題處置階段
在日常處置問題的階段,運維人員主要關注兩個核心指標:MTBF,MTTR。
MTBF:故障預防、故障根治階段的度量指標,需要持續提升,拉長故障發生的間隔周期。
MTTR:包含故障發現、定位、恢復時長。故障發生時需要有良好的多團隊協作機制,快速定位初因,故障預案執行迅速且不引發二次故障。
在這一階段運維人員可以從監控、告警、流程、自動化以及管理機制等多個方面著手處理,其核心目標就是將平均故障恢復時間(MTTR)盡可能降低,保障業務的連續性:
- 發現:通過監控,日志,鏈路等工具及時發現問題。
- 定位:通常會有大量告警產生,需要對告警進行抑制、降噪,對問題進行降維,對部分問題還需要與其他團隊協同定位,同時對于一些關鍵問題需要建立及時上升的機制。
- 根因:定位到問題以后,基于時間、關系進行更深一步降噪,對各類指標進行明細排查,同時通過日志、鏈路等工具的聯動確認根因。
- 恢復:恢復階段除了手動的操作以外,類似應用發布場景下,可以將發布操作,發布回滾等一些可復用場景進行自動化能力的積攢,以提高故障恢復效率。
- 記錄:通過問題本身的記錄,協作卡點的記錄,對問題做一些簡單的閉環,以支撐后續在復盤階段更加深入的分析故障根治。

7)事后根治與復盤
故障的根治并不代表能夠徹底消除故障,而是通過事后的復盤和一些處理手段的總結,能夠盡量減少同類故障的發生,同時在過程中通過對人員的管理和考核手段,做好良好的文化建設,避免“追責”、“甩鍋”、“自黑”、“賣慘”等不良文化,進行團隊可持續性優化和改進。
- 在實際生產中,可以采取以下措施:
- 如實記錄,留下經驗記錄。能夠為團隊提供相關場景和案例進行學習和參考。
- 對用戶(客戶)有交代,能夠給用戶營造出團隊的專業感。
- 對續規避措施的持續跟進和對改進效果的檢查也需要依賴故障詳細信息。
- 通過事后復盤,提煉出易用性,易維護性,健壯性等方面的潛在需求。

03. 組織管理:可度量考核
可觀測建設并不只是軟件或者工具的建設,在實際落地過程中,最終面向工具的還是“人”。除了工具的建設,可觀測的組織文化建設也是必不可少的。而是否對組織進行了合理規劃、組織之間是否能夠高效協同配合,是否建立了可度量的考核體系,對提升企業整體運維水平也起著十分關鍵的作用。
1)組織劃分
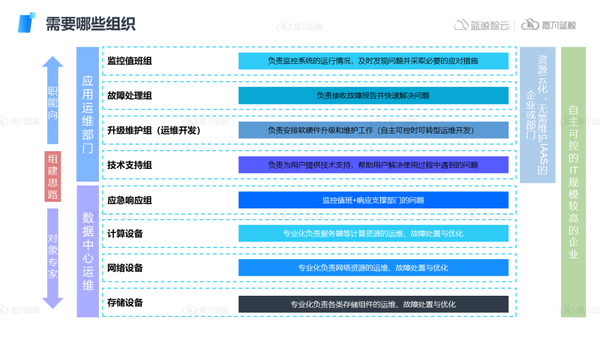
首先需要明確在故障處理全生命周期中,需要哪些組織的參與,通常我們的組建思路會分為上下兩部分:
2)向上
應用運維部門,這類組織面向的運維對象是多方面的,并不會專精于某一個對象之中,通常會偏向職能層面。
- 監控值班組:負責監控系統的運行情況,及時發現問題并采取必要的應對措施
- 故障處理組:負責接收故障報告并快速解決問題
- 升級維護組(運維開發):負責安排軟硬件升級和維護工作(自主可控時可轉型運維開發)
- 技術支持組:負責為用戶提供技術支持,幫助用戶解決使用過程中遇到的問題
3)向下
數據中心運維。更多組建的是對象專家團隊,分別對各類資源去設計組織,確保團隊的專業性,針對相應問題能夠有效提供解決方法。
- 應急響應組:監控值班+響應支撐部門的問題
- 計算設備:專業化負責服務器等計算資源的運維、故障處置與優化
- 網絡設備:存儲專業化負責網絡資源的運維、故障處置與優化
- 存儲設備:專業化負責各類存儲組件的運維、故障處置與優化
4)組織協同配合
組織間的協同與配合在許多企業中是較為棘手的,部分企業并沒有針對團隊協同做相關的建設,通常是靠人際關系來推動問題的解決,而建立良好的協作機制與完善的問題處理流程能夠大大提升企業組織效率,并實現可推廣的組織文化。
這里我們以組織間協作的常見流程ITR(issue to resolved)為例:
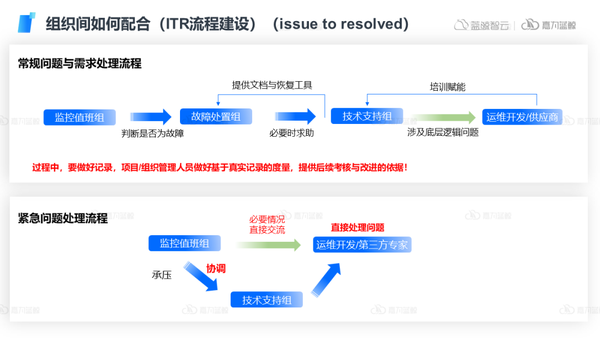
在常規問題處理過程中,要做好信息化的ITR流程記錄,同時做好基于真實記錄的度量,為后續的考核與改進提供有力的依據。
在緊急問題處理下,做好問題的上升,快速將無法解決的反饋到更加專業的團隊中,使得問題能夠得到更有效的處置,從而更快速的完成問題閉環。
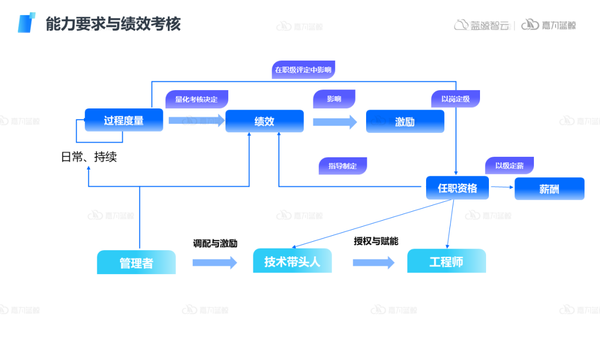
5)能力要求與績效考核
通常績效考核也是企業IT組織較為頭痛的問題。在績效考核上,核心是要持續不斷的做好日常工作的過程度量,從而才能夠量化考核決定績效指標,最終影響提現在激勵上。
同時整個過程的度量可以用于人員的職級評定的重要指標依據,管理者需要做好資源的調配與激勵規劃,同時在組織中要推動技術帶頭人不斷賦能工程師,團隊內部互相扶持進步,實現整體團隊的前進,從而形成良好的組織管理閉環。
04. 工具應用——匹配戰略戰術
1)可觀測工具:
在故障發現和恢復的第一階段,仍然是監控告警等觀測工具,對原始三大支柱數據:日志數據、指標數據、鏈路數據進行采集分析處理,基于這些基礎數據,做好監控告警策略的配置,實現事件的監控與發現。
2)自動化工具:
在故障處理的中期階段,主要是自動化的工具體系,在這一過程中積累一些自動化能力,實現簡單故障的自愈,復雜問題可以同時結合人為判斷和以往經驗沉淀進行處理,建立故障處置能力。一般來說自動化工具體系最好是與監控、告警等觀測工具相互結合使用,更高效的完成故障處理。

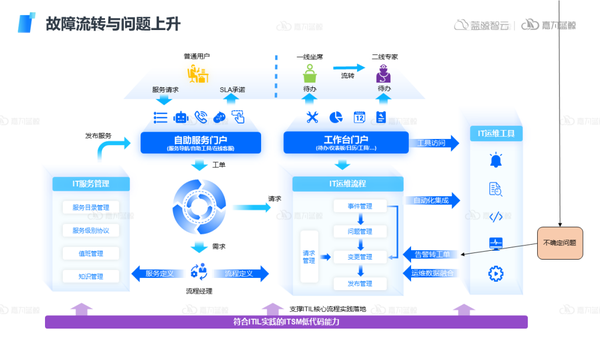
3)流程流轉工具:
對于一些不確定的、無法解決的復雜的問題,難以在IT組織內完成閉環的,可以通過流程體系的建設,做好故障的流轉與問題的上升。可觀測工具、自動化工具與流程體系的相互融合以達到故障的全生命周期管理。
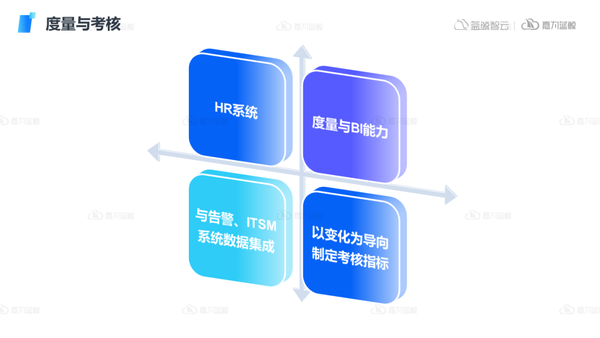
4)組織管理:
最后是結合上文對組織度量和考核的建設,對涉及到的HR系統、度量與BI能力、ITSM等進行相應的配套優化,以度量數據為基礎,以變化為導向制定考核指標,從而實現有效的組織管理。
可觀測的落地是一個龐大的工程,本期我們僅僅只從部分維度分享了關于戰略管理到工具落地的相關經驗,對于監控告警指標設計、日志管理、應用體驗優化等更加細分的內容,我們將在可觀測系列直播中進行更加深入的分享,如果您感興趣或有相應建設需求,歡迎聯系我們!











