01. 容器監(jiān)控痛點
近年來,Kubernetes 作為許多公司云原生改造的首選容器編排平臺,越來越多的開發(fā)和運維工作都圍繞 Kubernetes 展開,保證 Kubernetes 的穩(wěn)定性和可用性是基本需求,而其中的核心是如何有效地監(jiān)控 Kubernetes 集群,確保整個集群的高可觀測性容器監(jiān)控常常會有以下痛點:
- 動態(tài)環(huán)境與復雜架構(gòu)
容器化環(huán)境通常是高度動態(tài)和分布式的,這意味著容器生命周期短且頻繁變化,同時應用由多個微服務組件構(gòu)成,分布在多個節(jié)點上。這種動態(tài)性和復雜性要求監(jiān)控工具能夠快速適應環(huán)境變化,并有效地追蹤跨多個服務和節(jié)點的問題。
- 數(shù)據(jù)量大與性能開銷
高頻率的數(shù)據(jù)收集和大量的日志、指標數(shù)據(jù)會迅速增長,給存儲和處理帶來挑戰(zhàn)。另外,監(jiān)控系統(tǒng)本身引入的性能開銷也需要謹慎管理,以免影響應用程序的正常運行。
- 多層次監(jiān)控需求
容器監(jiān)控需要覆蓋多個層次,包括底層基礎設施、容器運行時、容器編排平臺,以及應用層面的性能指標和日志數(shù)據(jù)。
02. 場景介紹
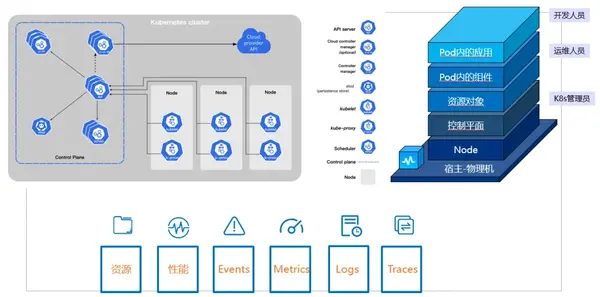
容器監(jiān)控,泛指在容器場景下,對容器環(huán)境的指標、事件等進行上報。目前市面上的容器管理平臺,基本被Kubernetes所統(tǒng)一,本文將核心圍繞Kubernetes的場景及特性,介紹嘉為藍鯨監(jiān)控中心(下稱“監(jiān)控中心”)是如何實現(xiàn)容器監(jiān)控的。
不同于常見的主機監(jiān)控、組件監(jiān)控等成就,容器監(jiān)控具備以下幾個鮮明的監(jiān)控特性:
- 監(jiān)控目標是動態(tài)的,無法通過傳統(tǒng)的方式對指定目標IP、目標端口進行監(jiān)控。
- 由于容器的頻繁銷毀與創(chuàng)建,監(jiān)控目標展現(xiàn)出極高的動態(tài)性,缺乏有效的監(jiān)控手段將直接導致難以追溯。
- 無需關注容器具體運行在哪臺機器上。
- 容器的數(shù)量多,上報的指標量級多。
圍繞著上面的特性,容器監(jiān)控的訴求主要分為以下幾點:
1)集群本身的運行狀態(tài)監(jiān)控,監(jiān)控的目的是隨時關注容量、及時發(fā)現(xiàn)異常,讓集群的運維者能夠快速修復集群問題。
- 對Kubernetes集群狀態(tài)的監(jiān)控,如Master集群的etcd,Kube-api、Kube-scheduler、Kube-proxy、Kubelet等核心服務的監(jiān)控。
- 對Node節(jié)點狀態(tài)的監(jiān)控,如CPU、內(nèi)存、網(wǎng)卡等監(jiān)控。
- 對資源的統(tǒng)計需求,如Cluster、NameSpace、 Node、Pod數(shù)量的統(tǒng)計。
- 對Workload、Service、Pod、Container運行指標和狀態(tài)監(jiān)控。
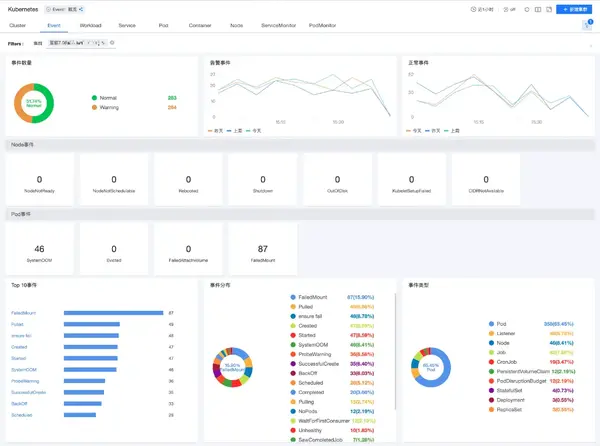
2)Kubernetes事件監(jiān)控記錄了組件的某個時間的動作,用于展示集群內(nèi)發(fā)生的情況,當集群內(nèi)的資源狀態(tài)發(fā)生變化時產(chǎn)生新的event,對容器事件的收集、監(jiān)控,避免集群或節(jié)點可用性產(chǎn)生的影響。
- 容器事件:如容器啟停狀態(tài)、拉取/創(chuàng)建/啟動容器失敗等;
- 節(jié)點事件:如節(jié)點添加/刪除、節(jié)點狀態(tài)變化、節(jié)點可用性等;
- Pod事件:如創(chuàng)建Pod成功/失敗、刪除pod成功/失敗等.
3)自定義指標的監(jiān)控:
- 對于運行在容器中的服務而言,僅僅依賴運行環(huán)境的指標正常性來評估服務狀態(tài)是不足夠的。因為即便運行環(huán)境(如CPU、內(nèi)存等)指標表現(xiàn)正常,因此需要上報服務本身的指標。
- 服務的指標,如接口的成功、失敗、飽和度、錯誤率等,通常這類指標對應用開發(fā)來說,更具有實際參考價值,更能夠?qū)I(yè)務有幫助。
03. 產(chǎn)品方案
對于K8s的監(jiān)控,其實已經(jīng)有一套原生的Prometheus方案,方案本身采集的指標相對完善,但是核心問題是對集群性能有較大的占用,且整體部署方式相對獨立,采集的指標無法結(jié)合其他監(jiān)控產(chǎn)品進行有效的消費。
為了讓大家統(tǒng)一集中管理監(jiān)控,將容器監(jiān)控與主機監(jiān)控,業(yè)務監(jiān)控等融為一體,監(jiān)控中心推出了容器場景的監(jiān)控能力。可以解決以下問題:
- 避免Prometheus服務在高負載情況下OOM,查詢無響應,可用性不高問題。
- 無需每個Kubernetes集群獨立部署Prometheus。
- 解決容器監(jiān)控和業(yè)務監(jiān)控割裂使用的問題,集中式查看監(jiān)控、告警,讓監(jiān)控數(shù)據(jù)在統(tǒng)一的地方消費使用,無需同時維護多套監(jiān)控系統(tǒng)。
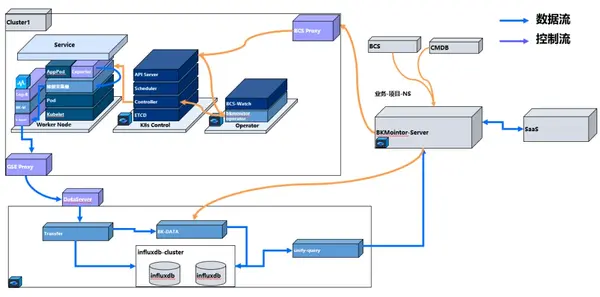
得益于監(jiān)控中心化的存儲能力,Bkmonitor-operator 較 Prometheus-operator 方案,對集群內(nèi)資源消耗更低。
04. 效果展示
1)容器多指標計算檢測
容器監(jiān)控的指標數(shù)量龐雜,許多指標均需經(jīng)過二次計算,甚至無法通過常規(guī)的配置方式配置檢測策略。對此,監(jiān)控中心同步提供以下兩個檢測能力:
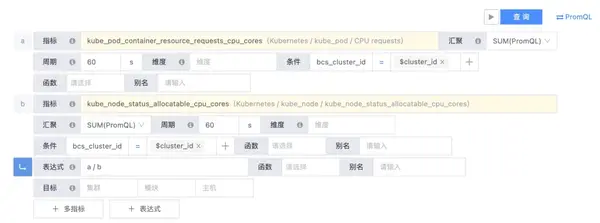
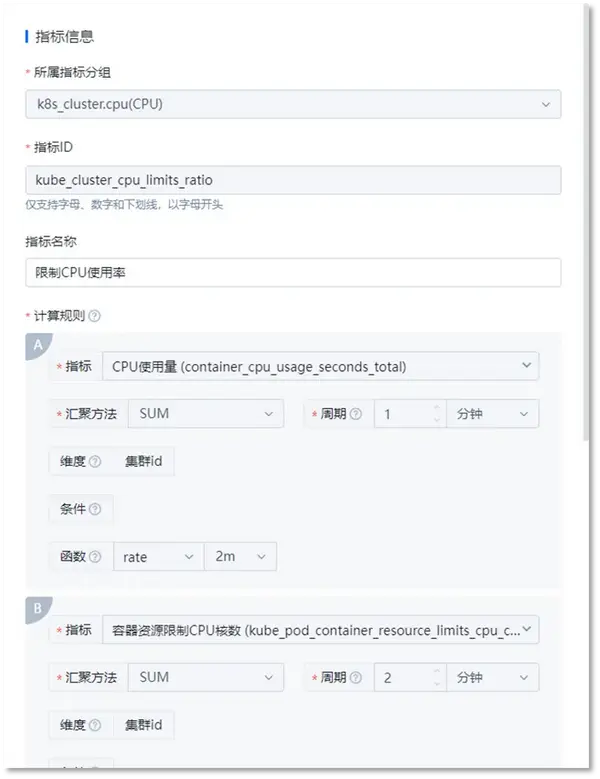
① 衍生指標管理
支持衍生指標能力,允許用戶通過指標計算自定義衍生指標。要知道,在容器內(nèi),許多上層資源指標都是由下層指標匯聚計算而來(比如Cluster的性能指標,其實是Pod性能指標匯聚計算獲得),通過衍生指標功能,用戶可以預定義上層匯聚指標,并在策略配置,可視化展示時直接消費,而不需要每次都重復配置計算規(guī)則。
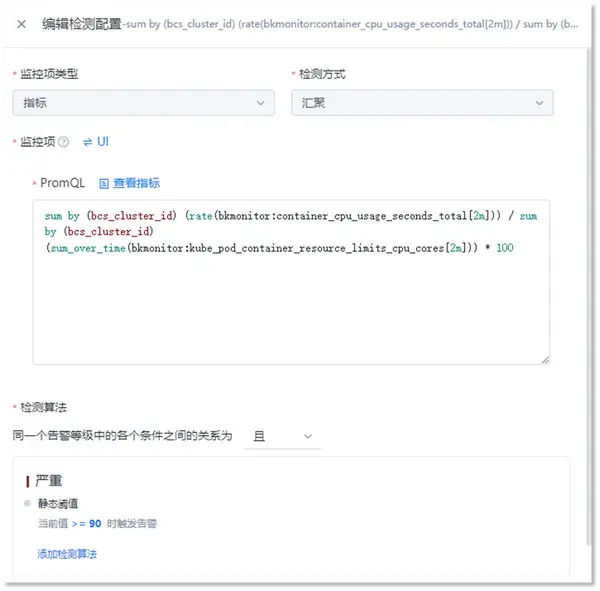
② 兼容PromQL表達式
完全兼容PromQL檢測預計,實現(xiàn)更多樣化的檢測邏輯,應對容器監(jiān)控下復雜的監(jiān)控檢測需求。
③ 容器資源監(jiān)控
監(jiān)控中心支持對容器內(nèi)各類資源對象進行發(fā)現(xiàn),并采集相關性能指標,包括以下對象:
- Cluster
- Workload (DaemonSet、Deployment、StatefulSet、Job、CrontJob、GameStatefulSet、GameDeployment)
- Pod
- Container
- Node
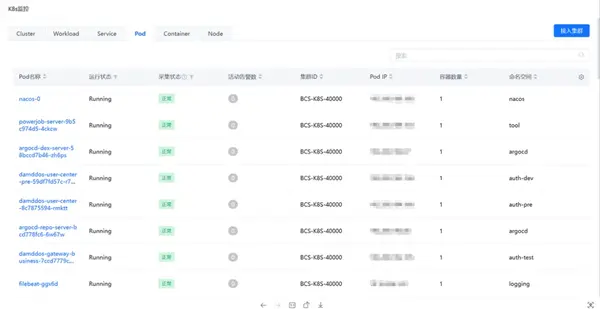
支持按照容器實例查看對應的實時指標視圖、告警數(shù)據(jù)以及實例本身的信息。
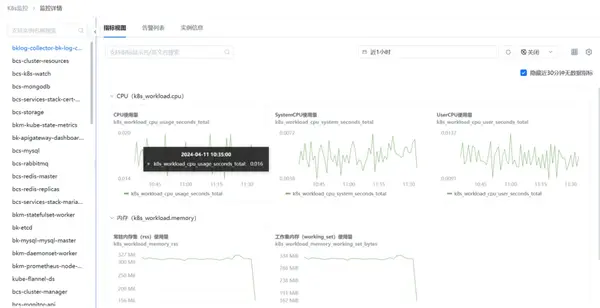
④ 容器組件服務監(jiān)控
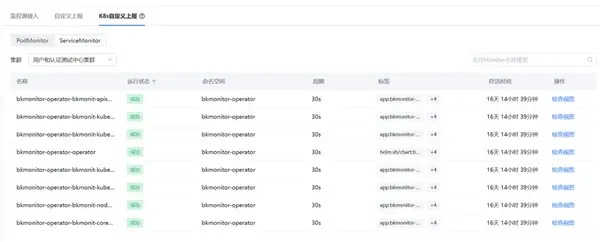
對于容器上部署的組件服務,監(jiān)控中心支持通過多種方式進行監(jiān)控:
- 支持serviceMonitor(主推)和PodMonitor;
- sidecar方式( 以sidecar模式部署exporter抓取器暴露出metrics,結(jié)合serviceMonitor進行采集);
- 中心遠程統(tǒng)一采集 (組件本身暴露了metrics,結(jié)合serviceMonitor進行采集)。
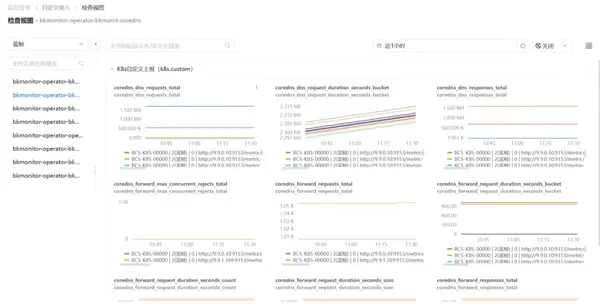
支持檢索查看上報后的指標實時數(shù)據(jù)。
⑤ 容器日志監(jiān)控
對于容器上的日志,監(jiān)控中心支持采集以下類型的日志:
- 支持采集在容器上運行的文件日志,即應用/服務產(chǎn)生的文本日志,例如Nginx日志、業(yè)務日志等;
- 支持采集K8s Node日志;
- 支持Kubernetes的標準輸出,即Pod容器的標準輸出,包含標準輸出信息(stdout)和標準出錯信息(stderr),輸出路徑為容器的/dev/termination-log文件。
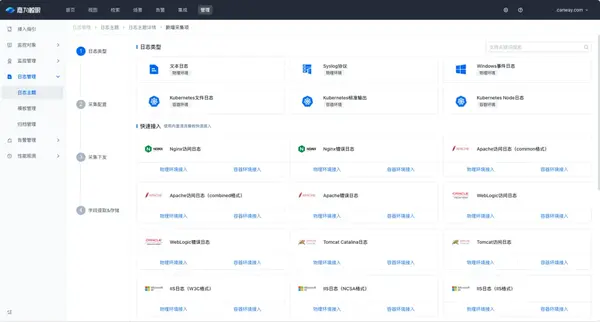
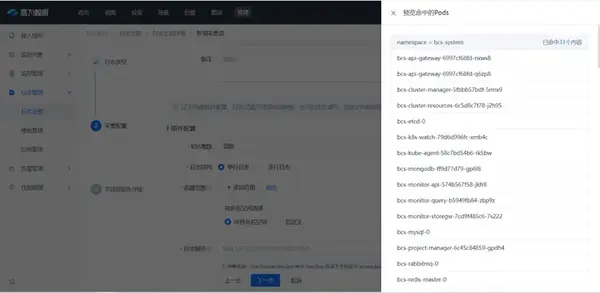
配置容器采集時可根據(jù)需要選擇指定的Pods。
05. 最佳實踐
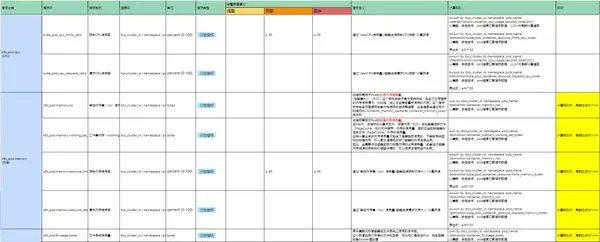
容器監(jiān)控場景由于自身的復雜性,即使在技術上我們實現(xiàn)了對目標的全量監(jiān)控、采集,但是如何配置有效的告警依然是用戶實施容器監(jiān)控的一大難點。
為了幫助在容器監(jiān)控場景下經(jīng)驗不深的用戶,監(jiān)控中心不僅內(nèi)置了默認的容器監(jiān)控策略、容器儀表盤,同時還提供了詳盡的指標說明文檔和最佳實踐配置指引,幫助用戶全面了解容器監(jiān)控數(shù)據(jù)。