在日常生活在,你的網頁、小程序、APP,是否有過以下情況?
當類似上述故障發生時,最痛苦的莫過于“救火隊”——運維人員,不僅需要耗費大量時間進行排查,而且不能很好定位到是前端的問題還是后端的問題,前后端IT人員的互相甩鍋,也導致問題遲遲無法解決。
我們以一些典型的場景為切入,來看看排障定位為什么會出現如此困境:
01. 運維痛點——排障過程存在困境
1)單點用戶排障流程
過去傳統運維單點排障的工作實錄:用戶紛至沓來,客服電話被打爆,運維人員看看堆積如山的工單汗如雨下。只能一個個工單進行故障排查。
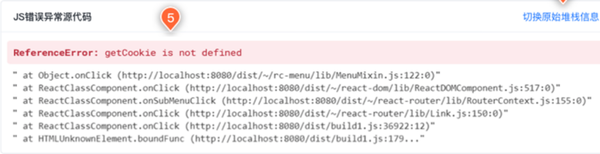
運維人員打開第一條工單,發現是個普通的JS錯誤報錯,但是只能看到異常錯誤堆棧信息,無法通過這個堆棧直接定位到錯誤的源代碼行。只能抱著這個異常錯誤去自行解析。好不容易解析出了源代碼異常的位置,并測試了幾輪,完成了源代碼修復。
運維人員打開第二條工單,解析完發現這是跟第一個一模一樣的錯誤源代碼行,也就是說,在完成第一個異常修復的時候,其實就已經同時完成了這條異常的修復。運維人員罵罵咧咧地打開第三條工單、第四條工單,一條一條解決著........
終于,在運維人員加班到十二點,解決完第433條工單,看著待辦1000+后。啪地一聲關上了電腦。
結果自己該做的其他工作,一點進度都沒有。
2)前端排障原理與流程
當然,隨著代碼技術的不斷演進,現在的程序員一般是不會一行一行的去排查代碼的,不然動輒上萬行的代碼,如此去排障,運維人員、前后端人員早就“崩潰”了。以JS異常為例,我們來看兩個實例:
① 簡單情況下的問題定位
大部分程序編寫過程中,程序引擎會有定位異常行號的功能,但當部分引擎不具備定位行號功能時,幾乎無法定位異常所在。在這種情況下,程序員們會使用TRY…CATCH語句,標記要嘗試的語句塊,并制定一個出現異常時的響應機制。
舉例:
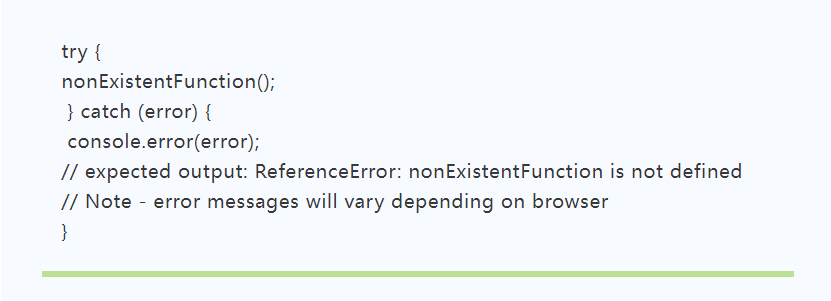
捕捉到異常之后,可以通過Error的lineNumber屬性將行號打印出來:

借此,完成異常代碼的定位。
② 復雜情況下的問題定位
當然,上例是比較簡單的代碼的情況,可以通過TRY…CATCH語句進行一條條的定位。
實際生產環境中,一般的網頁代碼都是體量較大的, 并且前端的JavaScript代碼在上線前都會經過壓縮、混淆處理,這樣的好處是可以減小代碼的體積,二來可以保證代碼的安全性。例如某網頁源代碼可能是這樣的:

在經過壓縮、混淆后變成了這樣:

在這種情況下,如果發生代碼報錯:

那么就很難根據錯誤信息去定位具體的代碼行。
該例子中還有 auto_renew 這個關鍵字,能根據關鍵字入手,實際情況可能更加復雜,如僅提示“Cannot read property [0] of undefined”時,定位具體問題將變得更加棘手。
③ SourceMap精準定位問題
如何解決復雜情況下的代碼異常定位問題呢?
如果不壓縮代碼,直接用源碼去進行發布工作,看似可以完美的解決異常,但是代碼體積將會非常巨大,同時安全隱患也無法忽視。那為什么在本地開發的時候,默認的也是打包后的文件,用chrome測試的時候為什么就可以看到源碼呢?這就不得不提SourceMap技術了。
所謂SourceMap技術,就是維護一個源代碼和壓縮后代碼映射關系用的文件,通過壓縮后的錯誤信息反向推出源代碼的具體錯誤行號。
例如上述代碼,map文件內容如下:

其中,最重要的內容就是mappings這一行。這是一個很長的字符串,分為了三層,記錄了一搜索前后代碼的映射關系。現在常用的的前端打包工具(webpack、gulp、rollup等)都支持這個SourceMap功能。
打包后類似:
另外需要注意,SourceMap是不會跟著打包后的js一起部署的,不然你的代碼很容易就被他人反推出來。所以需要在打包腳本過程中,將其中的.js和.map獨立出來。
借助SourceMap技術,通過合適的展示平臺,如嘉為鯨眼真實用戶監測中心,就可以在展示平臺中精確定位到異常錯誤行。
除JS異常外,前端還會有許多其它類型的異常,還存在種各種各樣的排障困境,但實際上,只要弄清楚造成困境的根本原因,從本質出發著手處理,問題就迎刃而解了。
02. 根因分析——前后端分離的監控差異
1)前后端監控的差異
在當下流行前后端分離開發的大趨勢下,APM技術(應用性能監測,也就是后端服務監測)也更多的被大家所認知。
當前,隨著用戶端的復雜度的上升以及精細化運營的需求上升,對流量層的監控已發展至第三階段,從專注于網絡、IT部件/組件的后端監控轉向前端后端一體化監控,從用戶端著手開始采集數據,同時在整個用戶體驗交付鏈條的每一個環節都要進行監控,完成基于云的端到端全棧應用性能管理。
從用戶端的角度看,用戶操作一條信息大致是通過如下流程的:
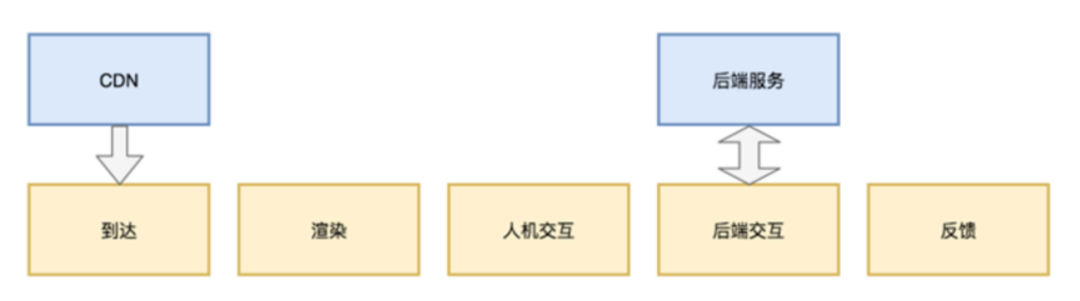
這其中的每一個環節都可能產生缺陷:
到達環節
- CDN資源加載錯誤
- 資源響應超時導致用戶跳出
渲染環節
- 排版錯亂
- 白屏或者模塊缺失
- 元素隱藏或遮蓋
交互環節
- 無法選中某些元素
- 無法取消/刪除/退出
請求環節
- 請求參數錯誤
- 網絡連接失敗
- 返回格式不正確
- 性能太差導致用戶放棄
反饋環節
- 結果無法確認,造成頁面假死或者重復提交
- 提供錯誤提示。
而在傳統的監控體系下,這一系列環節中只有后端交互的部分能夠用常規的后端監控工具,即APM覆蓋到,其它環節的監控往往是缺失的。
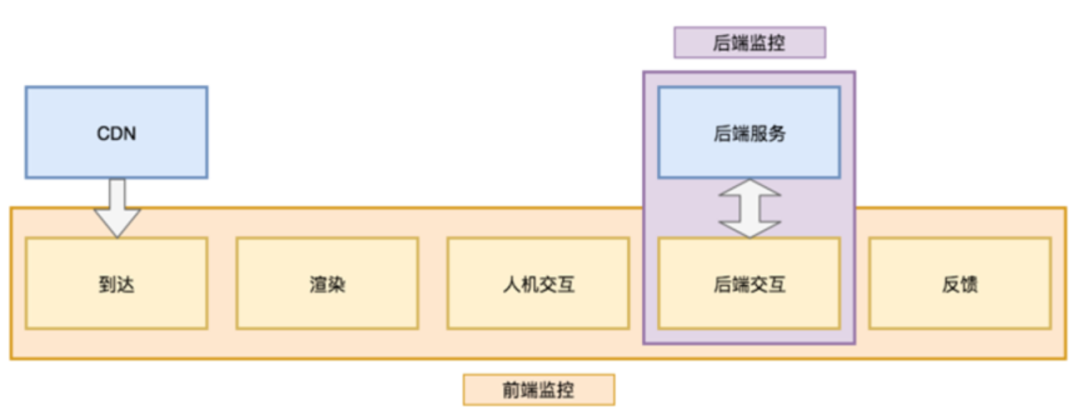
因為缺乏這方面監視的工具,前后端同事也經常進行問題的“甩鍋”。

為防止前后端的“撕逼”,我們需要從什么角度去建立前端監控體系,保證前后端的工作定位準確,精準排障呢?
03. 對癥下藥——跨越障礙實現精準排障
從用戶端來看,任何一個角度出現問題,都會導致用戶的體驗不佳,導致流失。為了保證用戶不流失,一些APM解決方案開始引入UEM(user experience monitoring)技術,即針對用戶體驗的監控,來保證可用性。
由于用戶端的復雜度不斷上升,我們面臨的偶發性缺陷,局部性缺陷等難以復現的問題會越來越多。
用戶端作為一個高度碎片化的系統,在任何個例上可用都不意味著整體可用,可用性問題實際上是按各種環境因素展開的概率問題。
影響可用性的環境因素:
- 地區 - CDN或者接口服務的可用性有地域差異
- 時間 - 部分業務邏輯受時間影響,包括本地時間、服務器時間、時區等因素
- 渠道 - 除了產品的主App之外,還可能有公眾號、瀏覽器應用、交叉推薦、運營推廣等各種合作渠道
- 版本 - 新老版本永遠共存,可能產生兼容性問題
- 賬戶 - 新用戶與老用戶,注冊賬戶與第三方賬戶
- 操作 - 用戶的操作方式可能是專業人員意想不到的
從這些角度出發去分析問題,就可以撅棄傳統的“反饋、復現、調試”的缺陷處理方法。通過前端主動上報監控信息的形式,收集更全面的用戶端數據,用“打點、觀察、分析”的方法,以統計學思維處理概率性的缺陷,而不是直接通過前后端一同還原現場深入細節排障的方式,就能夠避免甩鍋現象的發生。
前后端監控工具的相互聯動,能夠讓運維人員提供加強故障感知能力,保證業務連續穩定,同時也便于研發人員進行異常根因分析,精準定位問題,從而跨越前后端鴻溝,實現全方位排障流程的效率提升。











